

Remarque liminaire : Ce billet est écrit en écriture inclusive. Les pronoms neutres iel et iels sont utilisés en remplacement des pronoms il/elle et ils/elles, celleux pour celles et ceux, elleux pour elles et eux. Le point médian est utilisé pour inclure dans un même mot féminin et masculin : participant·e·s, utilisateur·trice·s. Les noms de professions sont féminisés lorsque cela est requis : une autrice.
convaincre un public non spécialiste
Le web sémantique, la puissance des données liées… Si vous êtes versé·e dans les problématiques d’accès à l’information, de génération de connaissances, de circulation, d’échange, de mise en commun d’information, tout cela fait un peu rêver.
Un triplestore, du rdf, du sparql, des ontologies, des URI… Si vous n’êtes pas féru·e d’informatique, tout cela au mieux n’évoque rien, au pire est repoussant.
Au moment d’ouvrir le triplestore de Persée, ces deux visions contradictoires nous sont apparues. Nous avons regardé ce qui se faisait ailleurs : comment d’autres institutions ouvrent-elles leurs métadonnées, quels usages sont prévus, mis en avant, comment convaincre un public non informaticien de l’intérêt de cette “nouvelle” façon de chercher des informations ?
Dans la plupart des cas, les triplestores sont juste ça : des entrepôts de triplets. L’utilisateur·trice a accès à un Sparql endpoint et l’éditeur·trice du site espère (en croisant les doigts ?) qu’iel saura s’en servir ou trouvera une personne compétente pour le faire à sa place.
Cette solution ne nous semblait pas satisfaisante. Facile et rapide à mettre en place, certes, mais pas satisfaisante. Notre objectif est que nos métadonnées puissent servir, au plus grand nombre, à ceux qui y trouvent un intérêt, c’est-à-dire, principalement, à des chercheur·se·s en Sciences humaines et sociales puisque c’est l’essentiel de nos contenus. Ce public n’est pas informaticien. Nous sommes rapidement arrivé·e·s à la conclusion qu’il nous fallait enrober notre triplestore d’une généreuse couche de médiation. De pédagogie. De vulgarisation.
Plusieurs questions méritaient qu’on s’y penche.
- À qui nous adressons-nous ?
- À quoi nos métadonnées peuvent-elles servir ?
- Comment amener ce public à s’approprier cet outil ?
À qui nous adressons-nous ?

Nous connaissons le public de Persée, une enquête a été menée il y a quelques années, elle faisait le portrait d’un public nombreux (plus de 30 millions de sessions de consultation par an) et fidèle (35 % des utilisateur·trice·s en lien avec la recherche ou professionnel·le·s de la documentation disent l’utiliser plus d’une fois par semaine et 35 autres pour cent au moins une fois par mois). Les deux tiers des visiteur·euse·s (66%) ont un lien avec la recherche (étudiant·e·s, masterant·e·s, doctorant·e·s, enseignant·e·s-chercheur·euse·s). Et 72 % se servent du portail dans un but scolaire/universitaire ou professionnel. Globalement, Persée est utilisé par des chercheur·se·s, des étudiant·e·s et des passionné·e·s.
Le public plus spécifique des métadonnées est plus chercheur, mais pas plus informaticien. Néanmoins, certain·e·s de ces chercheur·se·s peuvent s’adjoindre les services de chercheur·se·s en informatique et des informaticien·ne·s peuvent également vouloir accéder à nos données. Il faut donc prendre en considération ces deux publics, novice et expert.
À quoi nos métadonnées peuvent-elles servir ?

Les usages, c’est une vraie question. Nous pressentions que cette montagne d’informations (30 millions de triplets !) était un gisement précieux pour la recherche, mais nous avions besoin d’approches de chercheur·euse·s pour identifier ces usages.
Nous avons donc rencontré un certain nombre de chercheur·euse·s qui travaillent déjà avec les métadonnées pour savoir ce qu’iels y cherchaient et ce qu’iels y trouvaient.
Plusieurs usages-types généralisables ont émergé. La constitution d’un corpus, l’exploitation statistique de données chiffrées, l’exploration d’une carrière, d’une école, d’un réseau, la constitution d’une bibliographie.
Comment rendre cet outil utile, utilisable et acceptable

Le meilleur pour la fin…
Comment amener des chercheur·se·s qui ont l’habitude des moteurs de recherche à faire des requêtes Sparql ?
Première idée : on va faire un tutoriel Sparql. Un peu de théorie, quelques vidéos, quelques requêtes exemples, ça va rouler !
Hmm. En fait il existe déjà beaucoup de tutoriels Sparql, de moocs et de cours en ligne. C’est long, c’est technique, ce n’est pas accessible si on ne maîtrise pas un certain nombre de notions informatiques.
Sparklis
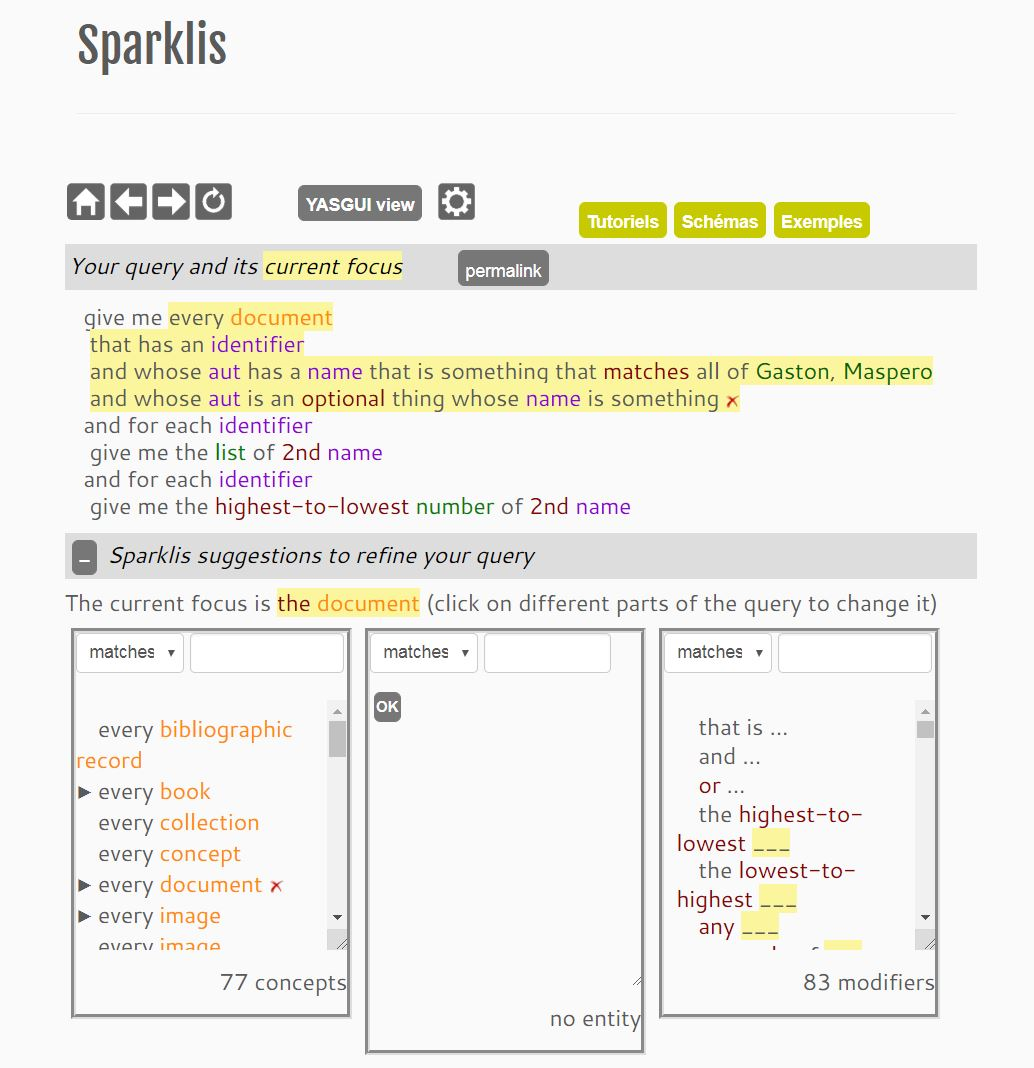
Nous avions la conviction qu’on devait pouvoir trouver un moyen d’interroger le graphe par un système de cheminement dans “l’arborescence” (ce qu’un graphe n’est pas, au sens strict, nous sommes d’accord) ou par menus déroulants. Heureusement, une bonne âme a mentionné le programme d’un enseignant-chercheur de l’Irisa, Sébastien Ferré, qui propose de générer des requêtes Sparql via une interface graphique : Sparklis. Cet outil permet de choisir le type d’entité et ses propriétés dans des menus déroulants qui s’adaptent au fil de la construction de la requête. On peut spécifier des noms, des mots, des dates puis opérer des tris et des regroupements sur les résultats de requête. Sparklis est une solution complète dans laquelle l’utilisateur·trice peut visualiser la requête Sparql que le programme a généré, télécharger les résultats sous forme de feuille de calcul et accéder directement aux menus Google graph pour créer des courbes, des histogrammes ou d’autres graphiques à partir de ses données.
Sébastien Ferré a tout de suite été très réactif et très enthousiaste à l’idée de nous laisser déployer sa solution sur notre site, merci à lui !
Une louche d’explications, une cuillère de vidéo, une pincée de tutos

Nous avons donc écrit des contenus théoriques et techniques, enregistré des vidéos tutorielles et conçu des requêtes exemples réutilisables, tout cela sur Sparklis.
Nous avons ajouté à cela quelques explications sur le web de données, sur l’histoire de notre triplestore et comment il a été “fabriqué”, des représentations graphiques de nos schémas de données, quelques outils de visualisation et un espace d’échanges entre utilisateur·trice·s et entre elleux et nous, pour leur apporter notre aide en cas de besoin, notamment.
Il restait à organiser tous ces contenus, cela fut fait lors d’un atelier d’idéation. Nous avons décidé de répartir nos pages dans trois menus : Explorer, Comprendre et Partager, en gardant toujours apparents les liens directs vers les pages d’exploration du graphe : Sparklis et Sparql endpoint.
Cécile Almonté, master Architecture de l’informatique – ENS de Lyon